Ya he presentado en otras ocasiones trabajos en el ámbito del análisis de datos aplicado a datos de contadores de energía. La mayoría de ellos con la involucración de mi (ex)compañero Mikel Lumbreras.
Dando un paso más allá, estamos dándole a una vuelta en cómo mejorar los procesos. Por una parte, mejorando la calidad de los datos de partida. Identificando y corrigiendo los errores y/o faltas de información en los datasets. Y por otra parte, identificando patrones de consumo que permitan ajustar más los modelos.
En este sentido, Mikel presentó recientemente un trabajo para la identificación de patrones de consumo sobre un conjunto de edificios. Una serie de procesos que agrupan los días de una serie temporal en base al perfil de demanda energética, de forma que se puedan desarrollar modelos específicos para cada uno de los patrones.
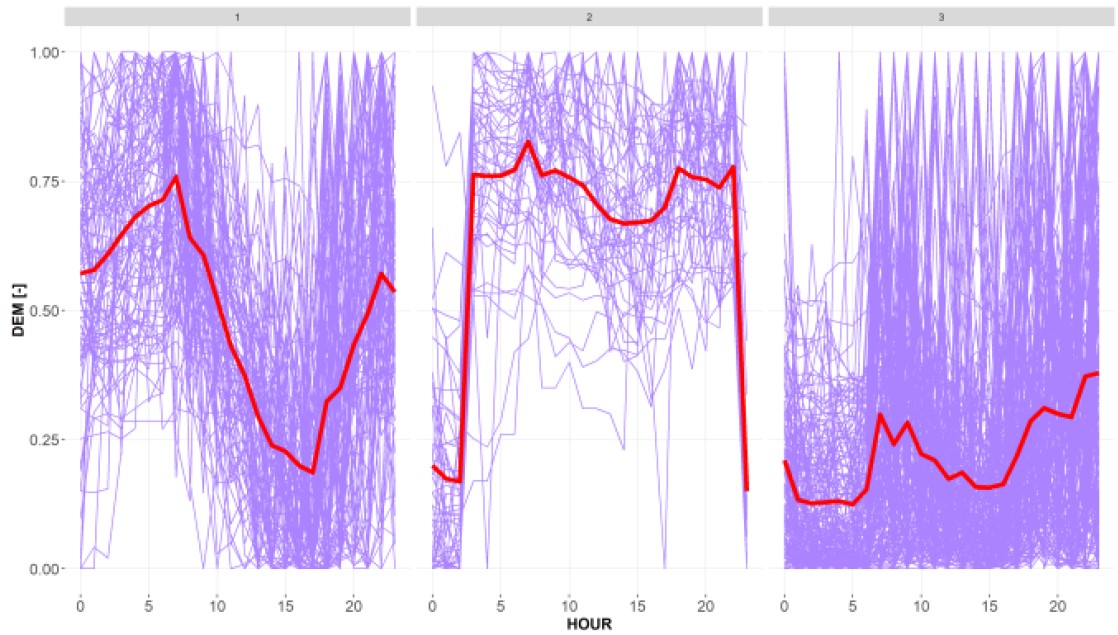
Uno de los primeros puntos importantes es definir lo que es un perfil de demanda. Para nosotros es un conjunto de datos que representan perfiles (horarios) de 24h de duración. Los perfiles se normalizan 0-1 en base al valor máximo.
De cara a evitar fenómenos anómalos, se identifican los outliers en base al algoritmo DBSCAN. La identificación de un valor anómalo implica la anulación de los datos correspondientes al conjunto de 24h en el que se integra. En este caso, con una serie de datos de buena calidad, se elimina aproximadamente el 2,5% de los datos.
La clusterización se realiza mediante el algoritmo de K-MEANS. En general, parece que la agrupación en 3 clústeres parece ser óptima. Aunque existe una segunda alternativa con 6 clústeres.
Los perfiles resultantes muestran los comportamientos siguientes:
- Perfil 1. Oscilante en el día. Máximo al inicio de la jornada laboral y mínimo a su finalización. Con valores intermedios en período nocturno
- Perfil 2. Perfil de demanda alta, con reducción nocturna
- Perfil 3. Estable.
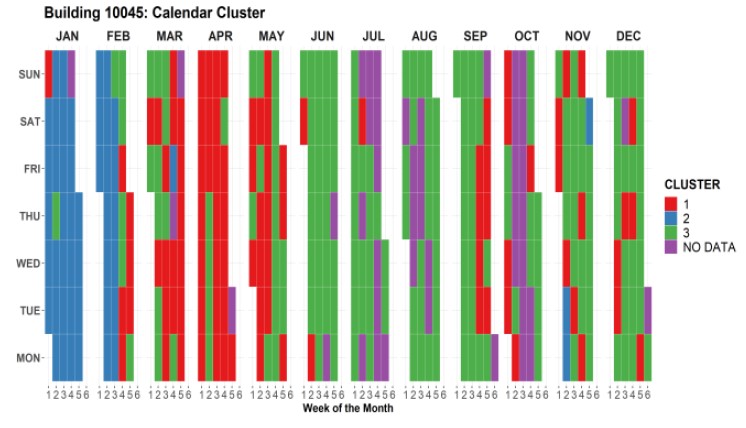
A priori, esperábamos un resultado que identificase claramente los festivos y los días laborables. Un poco en línea con un trabajo de Adrian Chong que revisé recientemente. Sin embargo, la identificación no resulta tan clara.
- Sí se ve una predominancia del cluster 2 en los días laborables del período invernal.
- El clúster 1 se centra en el período de primavera
- El cluster 3, en principio asociado a una carga térmica baja, se identifica en verano y otoño.
En general, creo que es un trabajo interesante, que busca aproximar formas de identificar los distintos comportamientos que ocurren en un edificio. A partir de aquí, se puede pasar a desarrollar modelos específicos para cada patrón.
Uno de los pasos que queda pendiente es desarrollar un modelo que permita prever el clúster al que va a ser asignado un día concreto sólo en base a información contextual (calendario y clima). Esto sería un punto clave para saber qué modelo aplicar a cada día.
El artículo es un trabajo conjunto de Mikel Lumbreras, Koldo Martin, Gonzalo Diarce, Rubén Mulero y yo mismo. Lo presentamos en la conferencia SPLITECH 2021, 6th International Conference on Smart and Sustainable Technologies. Por teleconferencia, fue una pena no poder acudir a Croacia.
La referencia completa al paper es la siguiente:
Mikel Lumbreras, Koldobika Martin-Escudero, Gonzalo Diarce, Roberto Garay-Martinez, Ruben Mulero, Unsupervised Clustering for Pattern Recognition of Heating Energy Demand in Buildings Connected to District-Heating Network, 6th International Conference on Smart and Sustainable Technology, 2021
El trabajo previo al que he hecho referencia es el siguiente:
Mikel Lumbreras, Roberto Garay, Antonio Garrido Marijuan, Energy meters in District-Heating Substations for Heat Consumption Characterization and Prediction Using Machine-Learning Techniques, Beyond 2020, Goteborg, 2020. IOP Conf. Series: Earth and Environmental Science 588 (2020), http://doi.org/10.1088/1755-1315/588/3/032007