Uno de los temas candentes en el ámbito de la energía en la edificación es buscar formas de predecir el consumo de energía en los edificios. Las aplicaciones de esto son múltiples, siendo la fundamental la posibilidad de modular el consumo fuera de los horarios de máximo costo de la energía.
Como muchos sabéis, esta predicción dista mucho de ser trivial, pues es única para cada edificio e inherentemente variable con criterios sociales y climáticos.
La relación con el clima están relativamente resuelta (tenemos algún trabajo en esta línea, tanto para edificios con District Heating, como para edificios terciarios), pero parece que los criterios sociales distan mucho de estar resueltos.
De hecho, cuando se habla del Performance Gap, generalmente se asigna una gran parte de la desviación de los modelos a la incapacidad de modelar correctamente el comportamiento de los usuarios.
Ya publiqué hace algunos meses cómo la rápida variación en el uso de los edificios lleva al fallo de los sistemas de predicción basados en IA. Supongo que ninguna inteligencia, ni humana ni artificial estaba preparada para adaptarse a esto.
Haciendo abstracción del efecto de pandemias, parece que se avanzaría bastante si fuésemos capaces de identificar un número relativamente pequeño, pero robusto de patrones de consumo para cada edificio. Y que fuésemos capaces de predecir correctamente qué perfil es el que se corresponde con las próximas 24h.
Sería posible identificar patrones específicos para días laborables, festivos, puentes, períodos vacacionales… Pero en este punto es necesario que la identificación se realice de abajo arriba. En base a los datos, para que los perfiles se correspondan con el uso real de los edificios, y no con una segmentación sesgada a priori.
En este sentido, los datos de consumo eléctrico son una buena fuente de información. Porque presentan tanto una dependencia climática (fundamentalmente consumos de refrigeración) y social (consumo de equipos eléctricos/electrónicos, iluminación…). De hecho, hace poco escribí sobre esto en base a un artículo del LBNL.
Sin embargo, para inferir patrones de uso específicos, es necesario abordar los perfiles de forma sistemática. En este sentido, el trabajo de clusterización de perfiles de consumo de energía de Adrian Chong me ha resultado muy interesante.
El primer paso para procesar los perfiles es proceder a su normalización 0-1 en base al máximo diario. Con este paso, se reduce sustancialmente la afección climática, pero se mantiene la información del comportamiento transitorio del edificio. De hecho, al normalizar sólo con el máximo (y no con el mínimo), se mantiene la información relativa a consumos estables en el edificio (equipos 24/7).
Como procesa un número relativamente amplio de edificios (81). Abajo se pueden ver los casi 30.000 perfiles diarios tras la normalización. Pero sí se empiezan a ver determinados perfiles típicos de los edificios, tales como el incremento de consumo sobre las 7h, y reducciones de consumo a las 15h, 19h y 21h (dependiendo del edificio).
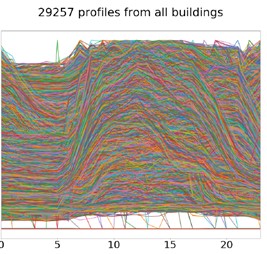
Es a partir de este punto donde empieza el trabajo de clusterización para la identificación de un grupo relativamente pequeño y robusto de perfiles. Realizándolo progresivamente, lo deja inicialmente en 221, para luego pasarlos a 6. Lo cual parece interesante. Más abajo dejo los perfiles identificados.
Lo más interesante de estos clústeres es que son relativamente fácilmente mapeables a los días de calendario por los que todos nos regimos. En la imagen siguiente, se pueden observar perfiles segregados para los fines de semana (edificios 1 y 2), festivos (edificios 1 y 2), y períodos vacacionales (edificio 3, residencia universitaria).
Sin conocer mucho sobre el calendario laboral de Singapur, se pueden identificar claramente los festivos de final de año (21 y 31 de Diciembre, 1 de Enero). Y viendo los perfiles del edificio 3, diría que los períodos lectivos van de mediados de Enero a Mayo, y de Agosto a Noviembre.
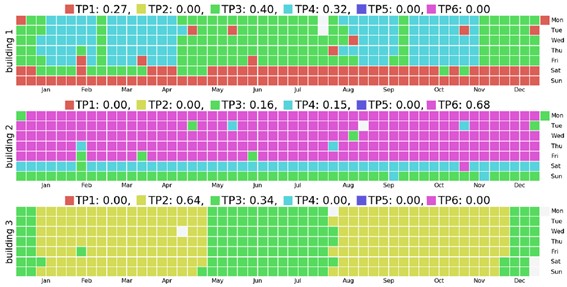
Con esto, parece relativamente posible, identificar patrones de uso para el año próximo, tomando el nuevo calendario laboral y los períodos lectivos universitarios. Por tanto, podemos emplear criterios de segmentación de modelos para inferir mejor una predicción de consumo. Bien para modularla y evitar los períodos de máximo coste de la energía, para definir buenas líneas base,…
Revisando los posibles puntos de mejora del método, veo varios.
- Para empezar, uno en contra de mi afirmación anterior sobre la normalización del máximo. Si observamos los perfiles 1-2-3 y 4-5-6 más abajo, observamos que los tres presentan los mismos fenómenos transitorios. Los perfiles 1-2-3 son básicamente estables, mientras que los 4-5-6 presentan un perfil típico de oficinas. Estos últimos presentan un incremento del consumo muy pronunciado a primera hora de la mañana, una situación ~estable a lo largo del día, y una caída progresiva del consumo por la tarde. Si se procediese a una normalización mínimo-máximo, podría ser posible reducir el número de patrones de comportamiento. Iría en contra del fenómeno físico a modelar, pero puede que caracterizase mejor el comportamiento humano subyacente.
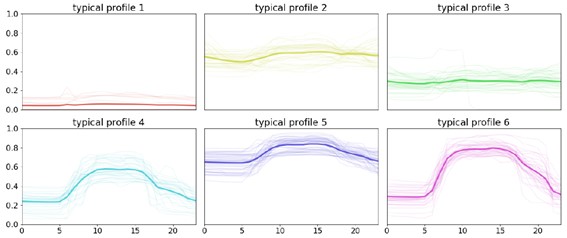
- Luego, aparentemente se asignan días sueltos a perfiles concretos sin motivo aparente. Esto puede que tenga que ver con los niveles de sensibilidad del método y el número de clústeres elegidos. Es casi más un tema de parametrización.
No tanto como punto de mejora, como por desconocimiento, no acabo de entender la parte final del método en el que se busca generar meta-perfiles que sean utilizables para un conjunto más grande de edificios. De hacerlo, se caería en generar patrones demasiado asépticos que cada vez sean menos asemejables al uso real de los edificios (motivo por el que se inicia todo este proceso). Puede que esto tenga que ver con la idea de aplicación futura que tienen los autores.
En general, me parece que el grupo de Adrian Chong ha hecho un trabajo muy solvente. Que indica que las aplicaciones de datos son el futuro, y que lo hace demostrándolo. Con un conjunto de datos grande y con mucha granularidad, y demostrando aplicaciones interesantes sobre él. A partir de aquí, se pueden aplicar estos métodos en múltiples dominios, tales como la identificación de patrones anómalos, benchmarking, predicción,…
Si os ha gustado este trabajo, os recomiendo visitar la web de ideaslab, dónde encontraréis más trabajos interesantes de este grupo. Con la ventaja de que tienen la sana costumbre de publicar los preprints (versiones completas de los artículos) así como los datos y el código fuente que se ha empleado en los artículos(https://github.com/adchong).
Entre otras cosas interesantes, han desarrollado eplusr y epwshiftr, para poder trabajar con Energy Plus y modificar achivos climáticos. Tengo pendiente hacer alguna prueba con esto, probablemente publique algo sobre sus posibilidades en unos meses.
El artículo original es el siguiente: Sicheng Zhan, Zhaoru Liu, Adrian Chong, Da Yan, Building categorization revisited: A clustering-based approach to using smart meter data for building energy benchmarking, Applied Energy, Volume 269, 2020, 114920, ISSN 0306-2619, https://doi.org/10.1016/j.apenergy.2020.114920.
El preprint está disponible para descarga gratuita en la siguiente ruta: https://ideaslab.io/publication/zhan-2020-building/