This year I´ve been lucky to co-supervise the MsC thesis of Bekbol Ismagulov. I briefly met him in 2019 in an MsC seminar on solar District Heating within SMACCs. And he contacted me back seeking some ideas for his thesis.
Together with my colleagues Aitor Erkoreka and Veronique Feldheim, and the support of Mikel Lumbreras, we asked him to work in the data preparation process.
People tend to think that data preparation is a highly tedious process (indeed, it is). It is needed before they actually start to get fun with model calibration and AI processes. But the more you know about model calibration, the more you realize how critical it is to have good datasets. Topics such as identification of faulty data, missing data… are critical if you want to calibrate models. Particularly if you deal with time series as we do.
And there is actually quite a lot of missing and faulty data around, even in the ages of IoT. In one of my last readings, between 5 and 10% of the data was not there.
The rationale behind the thesis was quite simple. We provided Bekbol some nice datasets coming from the district heating network in Tartu. This dataset was almost complete and could be considered as a “good quality” data source. So we told him: “Please erase some data and do your best to fill the gaps”. And he did so.
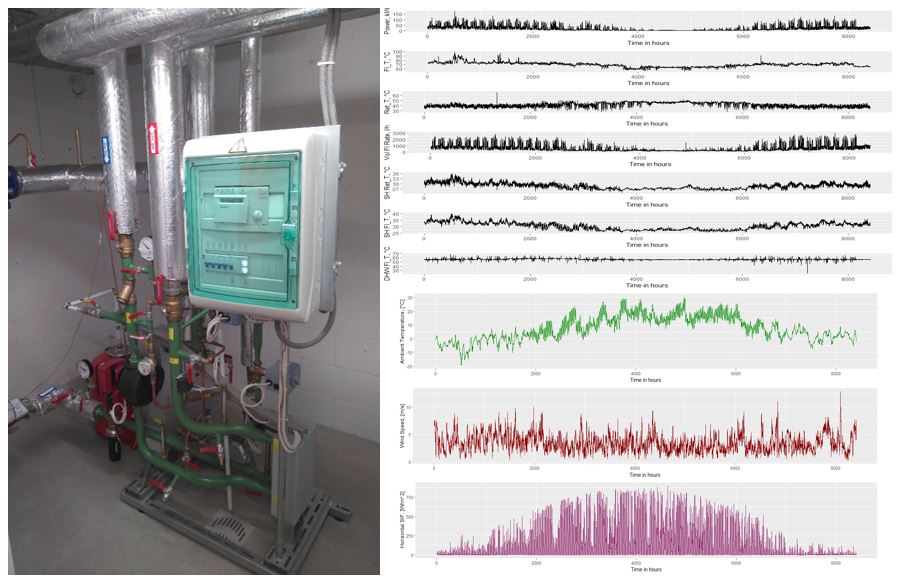
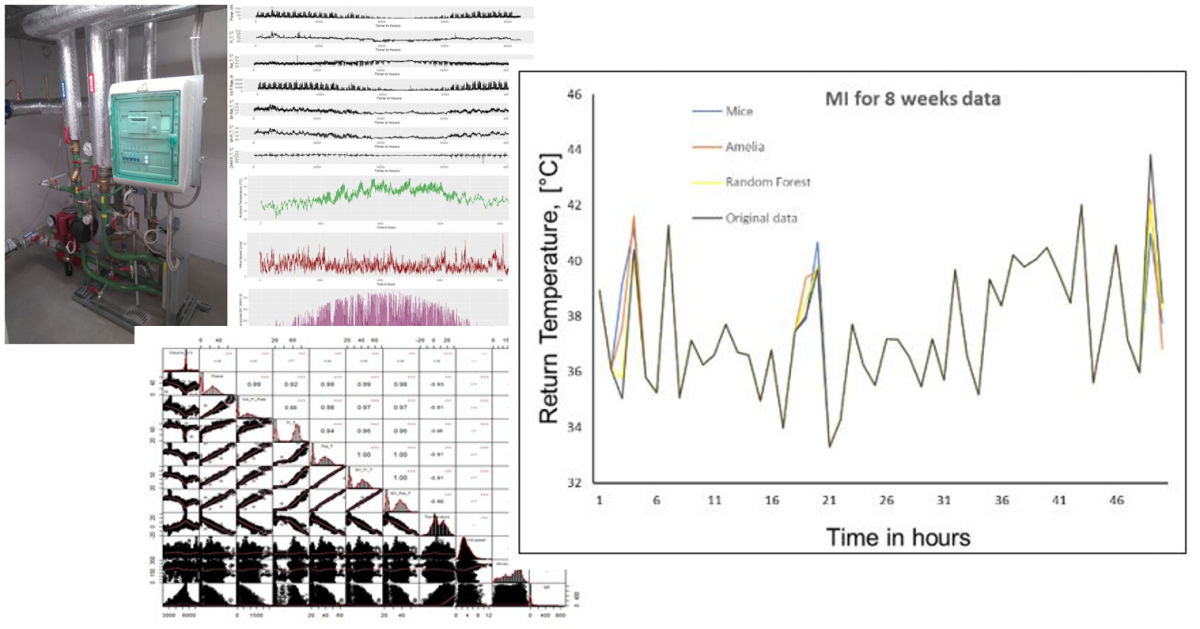
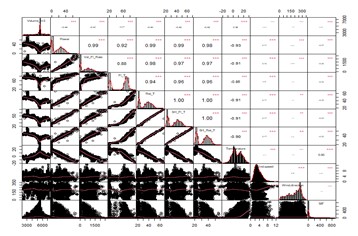
He worked in R and tried many methods. From most basic linear interpolation processes up to specialized libraries to fill the gaps in time series data. He did all this in a systematic way (it all starts in the correlation matrix) and tweaked the dataset and the algorithms to fill the gaps considering different modes of failure.
The key conclusions that I take from this work are the following:
- You learn a lot if you support highly motivated student in their learning process.
- Basic interpolation techniques are still very useful to fill small voids
- Specific libraries for multi-variate imputation such as Mice, Amelia and Miss-Forrest deliver quite promising results if you have signals correlated with your missing data.
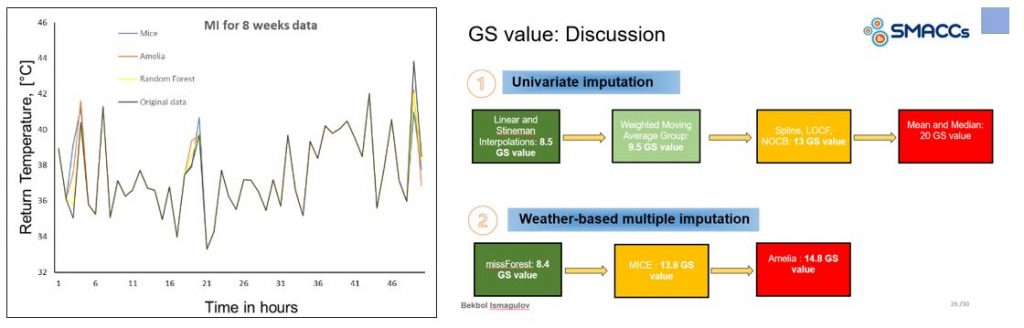
Actually, in the field of District Heating Data, you always have highly correlated data, as networks are populated with thousands of buildings. We might think we are special, but there may be 10s of users with similar patterns in the same district. In fact, some works on electric substations suggest so.
Personally, I did not have a previous experience with multi-variate imputation methods, so this was a great way to introduce myself to them.
Thanks Bekbol, It has been a pleasure.
Also special thanks to Margus Raud from GREN who kindly provided the data.