I have talked on my collaborations with Mikel Lumbreras in several previous posts. One of our recent activity was on how to use clustering to identify day types (“How will my building behave tomorrow?…”), which is extended into a full scientific paper at Journal of Building Engineering.
There, we focused on understanding and predicting hourly heat loads in buildings. Instead of building a separate model for each hour in each day of the week—as per a previous approach— we explored how data-driven methods, specifically unsupervised learning could help identify recurring daily patterns in energy use. By recognizing these, and mapping them to calendar and climate conditions, we were able to predict the “type of day”. Moreover, by knowing the “type of day” beforehand, we could propose specific sub-models that better met each pattern. Which improved the accuracy of our models in heating load predictions compared to assigning generic hourly model for an “average Thursday”.
If the number of patterns is lower than the number of days in a week, this also requires fewer parameters and reduces the number-of-parameters-to-size-of-dataset ratio, resulting in more robust models. I believe that this approach is better suited for practical deployment in diverse building contexts.
Formulas and drawings are nice, but these need to come with examples. So some months ago, I published a full repository. If you are interested, please have a look on GitHub: Building Heat Load Characterization and Clustering.
What does the code do?
This new repository offers a complete workflow for analyzing and predicting daily heating loads in buildings:
- It starts with data preprocessing, cleaning and structuring the heating load data to remove noise and handle missing values, which ensures higher quality input for subsequent analyses. This was already possible with one of my previous code releases.
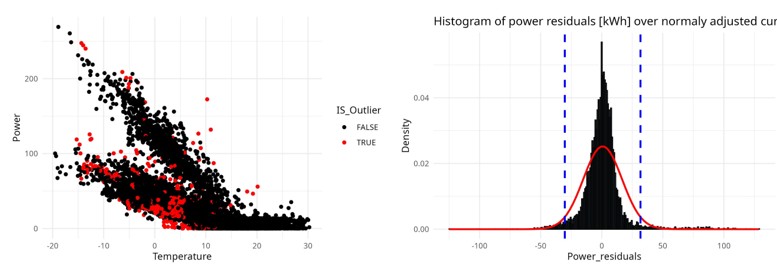
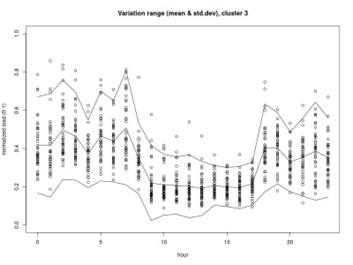
- Once the data is prepared, we get into the new material: the code applies clustering algorithms to group days with similar energy usage profiles. This unsupervised approach allows the method to identify typical daily patterns without requiring labeled data, making it broadly applicable across different building types.
- After the clusters are identified, the code implements predictive modeling by assigning each day to a specific cluster and using this information to anticipate the heating load for the following day. By focusing on representative “types of days” rather than modeling each hour independently, the approach simplifies the prediction task while improving accuracy and robustness.
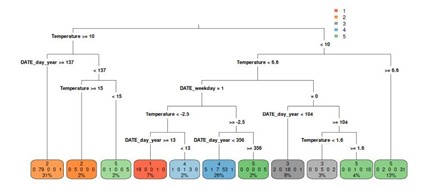
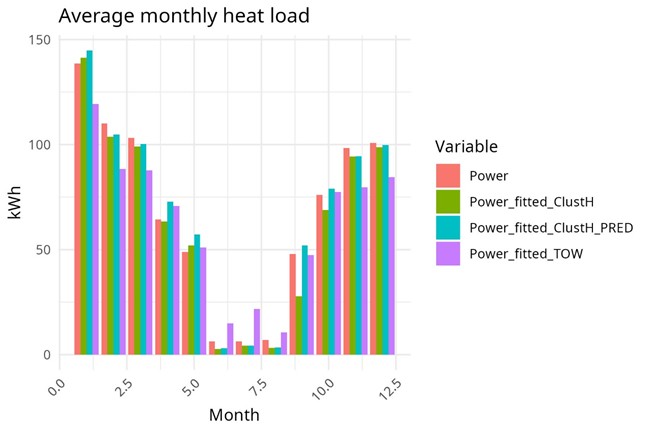
- The repository also includes visualization routines to inspect clustering results and evaluate prediction performance, helping users interpret the outputs and refine the models if needed.
Use of ChatGPT & learning for research contexts
I created this repository was created over the summer 2024-winter 2025 period. I also took advantage of this side-project to test AI tools (basically the free versions of ChatGPT, v3 and 4) and see the extend to which they were useful for scientific programming applications.
I consider myself a mid-career researcher with quite a good understanding of physics, but poor programming skills. AI tools allowed me to improve my coding and progress faster in most low-level programming issues. This was fantastic. With some practice, I ended up providing sufficient context to the tool so that the code generated by could be directly copy-pasted into R and executed smoothly 95% of the times.
But the tool failed (also on v5) to support me when asked for very specific scientific algorithms (i.e. “energy signature” or “changepoint”). It was actually quite funny because the tool suggested code with completely different physical/mathematical meaning each time. So I used part of the time spared in basic programming to work on these specific chunks of code (actually, it was mostly already coded in the preceding code repository).
I have to say that this is consistent with what I see when my students (particularly those younger than 30 and with little work experience, no matter if undergraduate or PhD) send-over documents/code to me. They typically provide texts that are grammatically correct, but that typically fail on the key scientific components.
Considering this, I asked for guidance within our faculty. After paying for a few coffees, someone suggested that the incorporation of AI should be handled twofold:
- If the student/colleague/… is sufficiently expert in performing the task to do, provide as many AI tools as possible. This will give them superpowers.
- If this is not the case, forbid the use of AI. Otherwise, they do not progress in their learning curve.
This seems quite reasonable, and I stick to this rule as much as possible.
Coming back to the repository itself, I am happy to say that it has been used by someone! I handed it over to Aitor Diez, who took it, adapted it to a different case, and used it for a few energy modelling tasks. Aitor is a very smart student in Informatics, so he found a few bugs. Thanks to him, these are now corrected (he might find a few more in the future). I would like to sincerely thank him for this.
References
New approach, comprising clustering of day types:
- Lumbreras, M., & Garay, R. (2023). Unsupervised recognition and prediction of daily patterns in heating loads in buildings. Journal of Building Engineering, 65, 105732. DOI: 10.1016/j.jobe.2022.105732
- Building Heat Load Characterization and Clustering: https://github.com/robgaray/Building_Heat_Load_Charact_Clustering
Previous time-of-the-week approach:
- Mikel Lumbreras, Roberto Garay-Martinez, Beñat Arregi, Koldobika Martin-Escudero, Gonzalo Diarce, Margus Raud, Indrek Hagu, Data driven model for heat load prediction in buildings connected to District Heating by using smart heat meters, Energy, 2022, https://doi.org/10.1016/j.energy.2021.122318
- Structured code for energy signature models: https://robertogaray.com/structured-code-for-energy-signature-models-for-heat-load-in-buildings/